2019. 4. 1. 11:35ㆍ풀잎스쿨 NLP Bootcamp
논문 링크: https://arxiv.org/abs/1802.05365
Deep contextualized word representations
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are
arxiv.org
발표자료: (염혜원 님 발표자료, Google Slide) https://tinyurl.com/yxuruba5
190330_Deep contextualized word representations (ELMo)_염혜원
Deep contextualized word representations (ELMo) 2019.3.30 발표: 염혜원
docs.google.com
참고자료: https://eagle705.github.io/cslog/2018/11/06/ELMo/
Deep contextualized word representations(ELMo)
요즘 Transformer가 나오면서 NLP관련 모델의 성능이 크게 증가했다.요즘 시대에 그냥 CNN이나 LSTM쓰면 옛날 사람 취급받을 것만 같은.. 또 하나의 breakthrough라고도 할 수 있을 것 같다. Word Representation쪽에서도 비슷한 도약이 있었는데, 그 시작이 ELMo다. 처음엔 그냥 성능을 약간 올려주는 모델인가보다 하고 넘어갔지만, 다양한 연구에서 활용되는 것을 보면서 이를 기반으로 현재는 Bert와...
eagle705.github.io
여태까지는 14~16년도 사이의 논문들을 살펴봤다면 이번 리뷰에서는 18년도에 나온 NLP 관련 논문인 ELMo에 대해 살펴보고자 한다. 해당 논문은 2018년도에 게재되었으며, BERT가 나오기 전까지 가장 활발하게 사용되던 방법 중 하나이다.
Abstract
지금까지 10주에 걸쳐 약 20개 남짓한 논문을 리뷰하면서 Language Model을 구축하기 위해 많은 시도들이 있다는 것을 봐왔었다. 그중 가장 대표적인 것들을 꼽자면 아마도 Character-level CNN이나 Word2Vec 일 것이다. 이러한 방법들의 공통점은 단어 자체나 단어의 Subword, 또는 각 글자를 이용한 Word Embedding을 사용한다는 점이다. 이런 방법들은 Discrete 한 특성을 가지는 단어들을 효과적으로 Continuous 한 공간(Space)에 표현할 수 있도록 만들어줬다.
하지만 자세히 살펴보면 이런 방식들은 단어의 Semantic/Syntatic 한 의미를 온전히 가진다고 할 수 있을까? 그리고 단어 자체가 여러 가지 방법으로 사용될 수 있거나 아예 다른 뜻을 가질 수 있는 단어라면? 이런 경우들에 대해서는 (Pre-trained모델을 사용한다고 하더라도) 기존에 사용하던 Word Representation만으로는 부족할 것이다. 바로 이러한 이유 때문에 여러 가지 방법을 통해서 모델을 구축하는 방법을 통해 하나의 Word Representation을 다른 용도로 사용하는 방법을 배우는 것이 현재까지의 모델이다.
이 논문에서는 이러한 문제점을 Deep한 Context의 표현을 통해 해결하고자 한다. 즉, Deep Contextualized Word Representation이다. 모델을 Deep 하게 쌓아서 각 Internal state를 통해 단어를 표현하는 방식을 사용하며, Internal state 간의 조합을 통해 여러 다양한 Representation을 가능하게 하는 Language Model을 만들고자 한다. 이것을 위해 Bi-LSTM을 사용하게 된다. 이러한 방식은 Embeddings from Language Models, 즉 ELMo라고 불리는 방식이다.
Contribution
Related Works
Abstract에서도 언급했듯이 기존의 Pretrained word vector를 통한 Word Embedding은 Context-independent 한 문제가 있었다. 따라서 이를 해결하기 위해 Subword 정보를 활용하거나 다의어의 경우 의미별로 다른 Word vector를 학습시키는 방법이 등장했다. (이 논문에서도 Character-Level Embedding을 통해 Subword의 정보를 활용한다)
따라서 Context-dependent한 Word embedding을 학습시키고자 하는 연구가 진행되었으며, 이에 대한 결과물로 Context2Vec, CoVe와 같은 다양한 방법들이 제시된 바 있다.
Architecture

ELMo에서의 가장 큰 특징이라고 한다면, 기존 LM에서는 Top LSTM Layer만을 활용하는 경우가 대부분이었다면 여기서는 모든 LSTM Layer의 정보를 활용한다는 점이다.
Input Layer는 Character-level Convolution을 통해 각 단어를 Embedding 하는 과정이다. 위 예시에서는 단순히 공백(space)을 기준으로 분류한 Word Embedding을 하고 있지만 실제로는 Word단위(나, 는, 머리, 를, 썼다)로 Tokenize 하게 되며, 각 단어를 Character 단위로 Convolution연산을 진행하게 된다.
Bi-LSTM Layer는 LM을 만드는 과정이다. Forward와 Backward의 양방향으로 진행하면서 각 방향에서의 확률의 합을 최대화하도록 학습시키게 된다.

여기서 각 Layer들은 Task에 특화된 결과물을 가지게 되며, 마지막 과정인 ELMo 임베딩 과정에서 task에 특화된 각 Layer의 representation을 조합을 학습하게 된다. 이렇게 학습되는 ELMo는 대부분의 Word Embedding과는 달리 문장 전체에 대한 Embedding을 학습하게 된다. 즉 Input sentence에 대한 함수라고 이해할 수 있다.
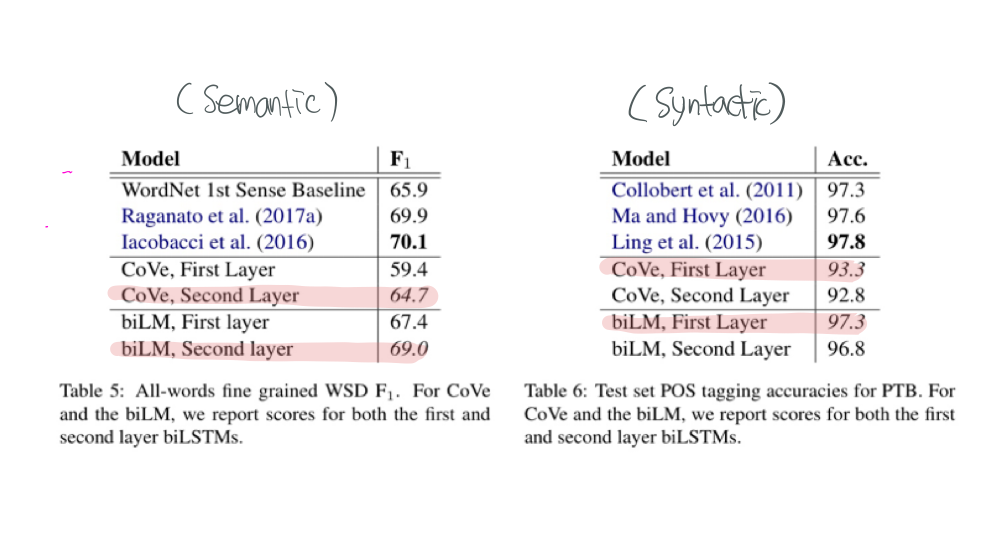
각 Layer가 어떤 정보를 학습시키는가에 대한 결과물도 확인할 수 있다. 위 결과를 보면 Semantic 의미에 대한 부분은 두 번째 Layer가 더 많이 학습하고 있고, Syntactic 의미에 대한 부분은 첫 번째 Layer가 더 많이 학습하고 있는 것을 알 수 있다.
추가적인 요소로는, Input에 대해 Skip Connection(Highway Network)을 활용하여 학습한다는 점이 있다. 또한 너무 Task specific해지는 문제를 방지하기 위해 weight normalization을 적용한다.
How to Use
ELMo를 Supervised 모델에 추가하기 위해서는 biLM의 weight를 고정시키고 토큰 벡터와 ELMo의 Output을 Task에 대한 RNN의 Input으로 사용하면 된다. 일부 Task(SNLI, SQuAD)에서는 ELMo벡터를 Task RNN의 Output에 다시 Concat 하는 것이 효과가 있었다는 결과도 있다.
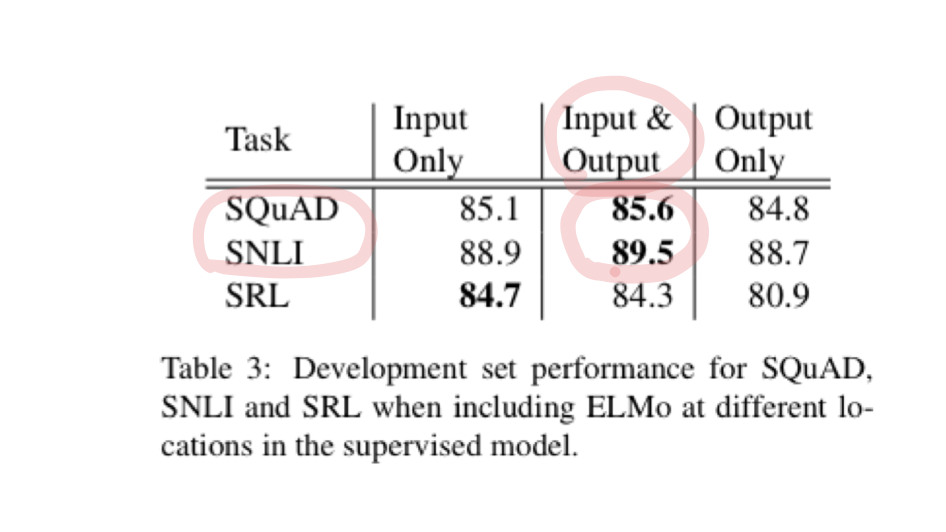
Result & Conclusion
Result
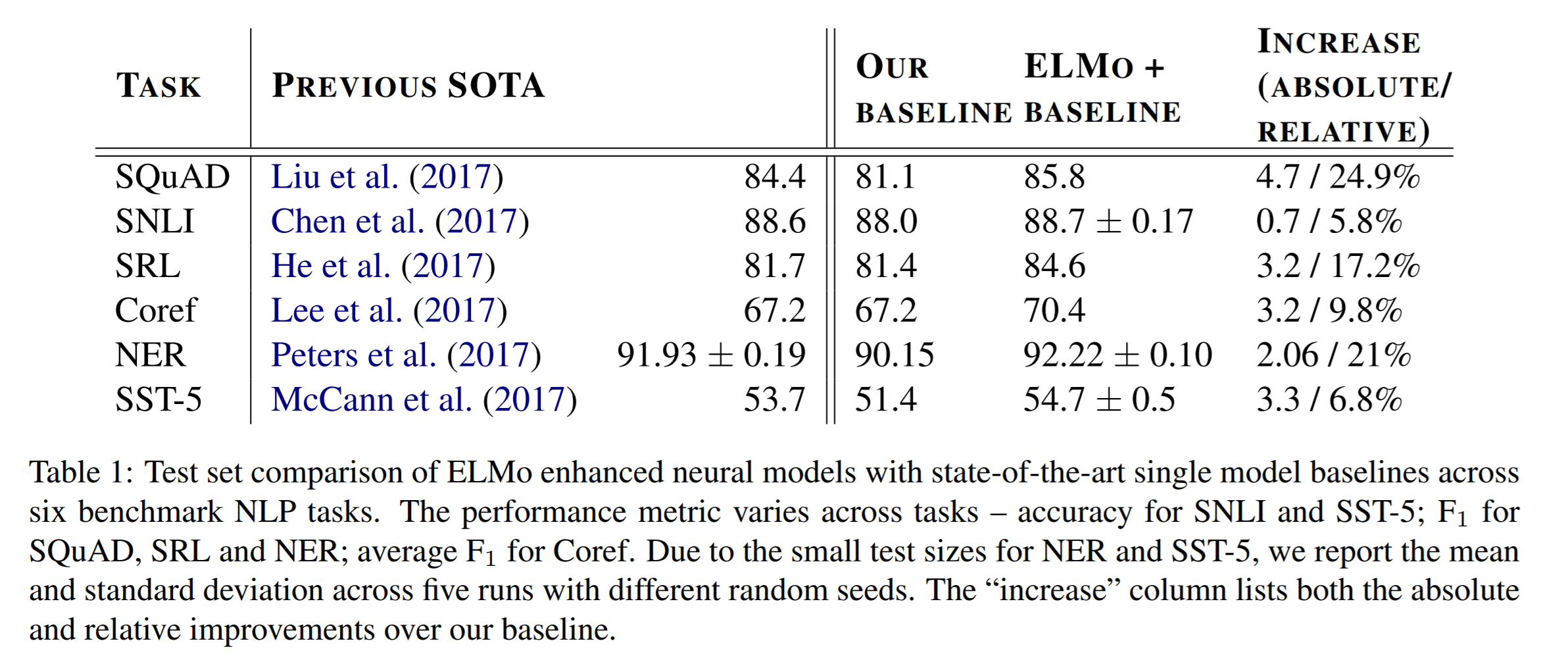
위 테이블은 기존의 모델은 그대로 유지한 채 ELMo를 적용했을 때의 결과에 대한 Benchmark를 보여주고 있다. 총 6개의 Task에 대해 모두 이전 SOTA를 보여줬던 모델들에 비해 향상된 결과를 보여주고 있는데, SNLI, Coref, SST-5의 성능 향상은 다른 3개의 Task에 비해 덜 높아진 것을 볼 수 있는데, 이는 Task의 특성상 Task-specific 한 문제를 풀기보다는 General 한 문제를 푸는 경우이기 때문이다.

위 결과는 Regularizer 설정 시 Gamma 수치를 어떻게 설정했느냐에 따른 결과이다. 즉, Regularizer를 강하게 설정하는 것보다 약하게 설정하는 경우가 더 좋은 결과를 보여주고 있다는 뜻이다. 다시 해석해보면 ELMo에서 받아들이는 정보가 Task를 풀기 위한 정보가 많이 포함이 되어있다는 뜻도 된다.
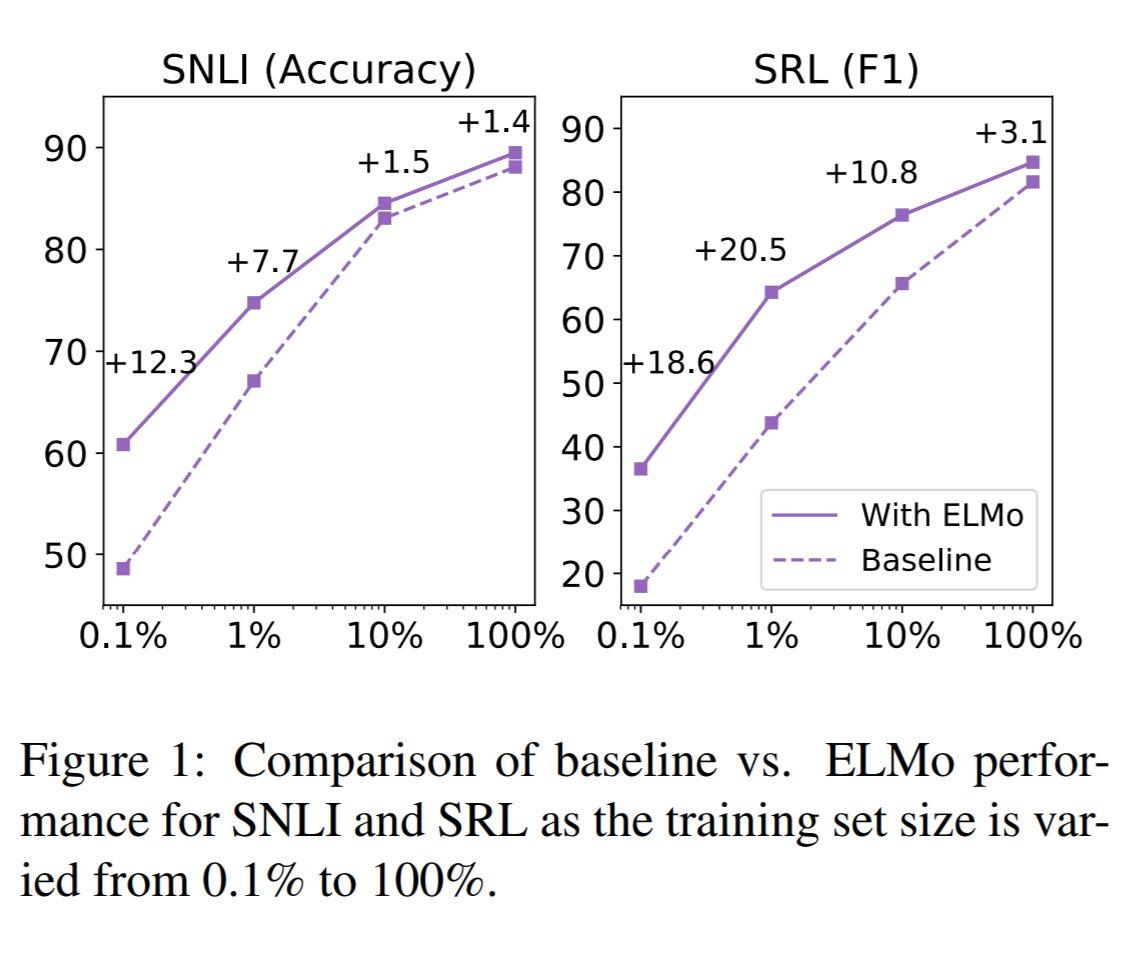
ELMo의 유무에 따른 학습 정확도에 대한 결과이다. 학습을 할수록 정확도가 높아지는 부분은 동일하지만 ELMo를 사용할 경우, 사용하지 않을 때에 비해 학습이 더 효율적으로 이뤄지는 것을 볼 수 있다.
Conclusion
ELMo라는 방식은 우리가 Word Embedding을 얼마나 효과적으로 하는가에 대한 부분이 NLP Task의 performance에 많은 영향을 끼친다는 사실을 보여준다. 이는 Word Embedding이 얼마나 중요한지를 보여주는 부분으로 이해할 수 있다.
사실 ELMo가 사용하는 방식은 word embedding이 아닌 sentence embedding이라는 사실을 생각해보면, 혹시 sentence embedding이 더 효과적으로 될 수 있을까? 아니면 sentence embedding이 아닌 paragraph embedding과 같은 방식도 가능할까에 대한 의문점도 생기게 한다.