2019. 4. 2. 20:57ㆍ풀잎스쿨 NLP Bootcamp
논문링크: https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
참고자료: (김현우님 발표자료)
추가참고자료: http://nlp.seas.harvard.edu/2018/04/03/attention.html
The Annotated Transformer
from IPython.display import Image Image(filename='images/aiayn.png') The Transformer from “Attention is All You Need” has been on a lot of people’s minds over the last year. Besides producing major improvements in translation quality, it provides a new arc
nlp.seas.harvard.edu
추가참고자료2: https://github.com/YBIGTA/DeepNLP-Study
YBIGTA/DeepNLP-Study
딥러닝 자연어처리 스터디의 논문 구현 코드 및 스터디 자료 모음 공간입니다. Contribute to YBIGTA/DeepNLP-Study development by creating an account on GitHub.
github.com
Abstract
Transformer 이전의 SOTA 모델에서는 RNN + Encoder/Decoder + Attention을 이용한 모델이 주를 이뤘다. 이중에서도 앞의 RNN에서는 Encoder에 필요한 정보를 압축된 형태의 Matrix로 전달하기 위해 사용되었다.
RNN 구조는 Sequence의 순서에 대한 정보를 최대한 온전하게 가져갈 수 있다는 점에서 중요한 이점을 가져갈 수 있지만, 여러 방법을 사용함에도 불구하고 여전히 Long-term dependency에 대한 부분은 문제로 남아있었다. 이러한 문제를 해결하는 방법으로써 Attention이 제시되었는데, Attention을 사용하는 방법은 주로 RNN이나 Encoder/Decoder 모델의 Output을 그대로 받는 형태로 사용된다.
이러한 방식의 Attention 사용법은 Long-term dependency의 문제를 해결하는데 좋은 성능을 내는 것에는 틀림이 없었다. 하지만 RNN의 특성상 이전 Hidden State/Cell State를 사용해야 하기 때문에, 순차적인 계산이 이뤄줘야 한다는 점에서 Parallelization과 같은 방법을 쓸수없다는 점에서 연산/학습 속도에 좋지 않은 영향을 끼침으로써 Bottleneck이 되는 문제점이 있었다.
이 논문에서는 Attention과 Encoder/Decoder모델만을 사용하는 방법을 통해 Long-term dependency를 해결하면서 동시에 parallelization이 가능한 모델을 제시함으로써 병렬처리에 적합한 모델을 제시한다.


Contribution
시작하기 전...
사실 RNN에서 병렬처리가 불가능하다는 점 때문에 이전에도 Dilated Convolution을 통해 학습하고자 하는 방법이 제시된 바 있다. (7주차 논문(2) - Neural Machine Translation in Linear Time) 해당 논문에서는 ByteNet이라는 구조를 통해 Encoder/Decoder를 이용한 Language Model을 제시한 바 있다.
하지만 ByteNet에서도 문제는 존재한다. Attention을 계산하고자 하는 두 요소가 멀리 떨어져있다면 연산량이 많이 필요하며, 이와 같은 문제점때문에 ByteNet에서도 Long-term dependency문제는 여전히 존재한다. 이러한 문제를 이 논문에서는 Self-Attention이라고 불리는 방식을 통해 CNN이나 RNN을 사용하지 않는 방식으로 해결하고자 한다. 이 논문에서 제시하는 모델인 Transformer는 처음으로 CNN이나 RNN을 사용하지 않는 방식이다.
Model Architecture

이 논문에서는 Transformer라는 모델을 통해 Attention만을 사용하여 Language Model을 학습시키고자 한다. Transformer는 크게 몇가지 부분으로 나눠볼 수 있다.
- Encoder/Decoder (x6)
- Sub-layer + Residual Connection
- Multi-head Attention + FFN(Feed-forward Network)
- Layer Norm + Dropout + Label Smoothing
- Positional Encoding
- Embedding
전체적인 구조는 다음과 같이 구현할 수 있다.
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
아래에서는 각각의 세부 요소에 대해 코드와 함께 살펴볼 것이다.
Encoder/Decoder
Encoder는 6개의 동일한 Layer(N = 6)로 구성되어 있다. Python으로는 아래와 같이 구현할 수 있다.
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
모델을 잘 보면 2개의 Sub-layer에 Layer Normalization후, Residual-connection을 적용한 것을 알 수 있다.
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
다시 말하면, 각 Sub-Layer는 아래와 같은 형태를 띈다는 것을 의미한다.
LayerNorm(x + SubLayer(x))
SubLayer 각각에는 다시 더해지고 Normalize되기 전에 Dropout을 적용해준다.
여기에 Residual Connection을 용이하게 적용하기 위해 model의 output dimension은 512로 설정한다.
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
각 Layer는 2개의 Sub-Layer를 가지는데, 한쪽은 Multi-head Self-Attention방식을 사용하며, 다른 한쪽은 단순 Position-wise fully-connected Feed-Forward Network를 사용한다.
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
Decoder
Decoder역시 6개의 동일한 Layer의 묶음로 구성되어있다.
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
Decoder에서는 Encoder에서 2개의 Sub-Layer를 사용하는 방식에서 추가로 1개의 Sub-Layer를 더 구성하게 된다.
이 Layer에서는 Encoder 묶음의 Output에 대해 Multi-head Attention을 적용한다. 그리고 Decoder에서도 Encoder와 비슷하게 Layer Normalization이후 residual connection을 사용한다.
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
또한 Decoder의 Sub-Layer에서 사용하는 Self-Attention방식을 조금 변경할 것이다. 이는 ByteNet에서 사용했던 방식을 생각하면 이해하기 용이한데, 해당 position에 대해 Attention을 계산하기 위한 부분에서 해당 position의 time step보다 앞선 Attention을 막아줄 것이다. (사실 t에 대한 Attention을 계산하기 위해 t+1의 정보를 가져다 쓰는 것은 좋은 구성이 아니라는 사실을 쉽게 알 수 있다.)
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0위 단계에 대한 부분을 그림으로 표현하면 아래와 같다.

즉, t에 대한 Attention을 계산하기 위해 t+1이상의 정보를 가져다 쓰지 않는 것이 핵심이다.
Attention
Attention은 Query와 Key-Value쌍과의 관계를 Output으로 mapping해주는 작업이라고 생각할 수 있다. (여기서 Query, Key, Value, Output은 모두 vector이다) 여기서 output은 value를 모두 weighted sum 한 결과인데, value에 적용하고자 하는 weight는 query와 key간의 학습된 연관성을 기준으로 계산할 수 있다. 즉, Query가 어떤 key와 얼마나 높은 확률로 관련성이 있는지 계산해서 다시 Value와 곱해주는 과정이다. 이러한 Attention방식을 'Scaled Dot-Product Attention'이라고 한다.
Scaled Dot-Product Attention에 사용되는 input은 d_k차원의 query와 key, 그리고 d_v차원의 value가 된다. 이 과정에서 모든 key에 대해 query를 내적(dot product)하며 각 결과값을 √d_k로 나눈 후 softmax를 적용하여 value에 적용하고자 하는 weight를 계산하게 되는데, 이는 d_k가 커질수록 내적 값이 커지면서 softmax의 값이 편중될 수 있기 때문에 scaling을 해주고자 하는 것이다. (여기서 주의해야 할 점은 key와 value는 value에 weight가 곱해지기 때문에 같은 vector가 아니라는 부분이다.)

def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
Multi-head Attention
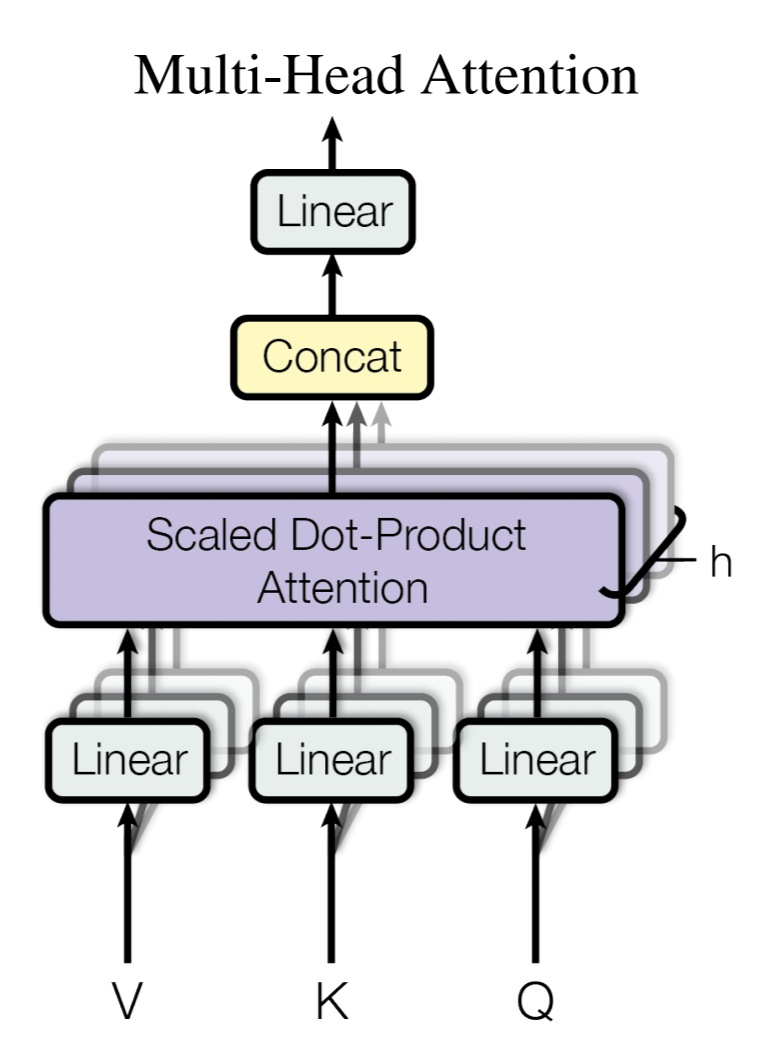
Multi-head Attention에서는 query, key, value를 바로 사용하는 것이 아닌 h번(h = 8)의 Linear projection을 따라 서로 다른 representation의 조합으로부터 Attention을 계산하는 방법이다. 이러한 방법은 이전 논문인 Bidirectional Attention Flow(BiDAF)에서도 사용되는 방법인 것을 생각해보면 생각보다 이해하기 용이하다.
사실 여기서 8번의 연산만큼 계산 비용도 8배로 늘어날 것으로 이해하기 쉬운데, Linear projection단계에서 차원을 줄여주게 되므로 연산량 자체는 비슷하게 되는 것이 특징이다.
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
Position-wise Feed-Forward Networks
Encoder/Decoder의 각 Sub-Layer에는 Fully-connected feed-forward network가 포함된다고 앞서 언급한 바 있다. 여기서 FFN은 각 position마다 적용되게 되는데, 아래와 같은 형태의 Linear transformation을 적용한다.
FFN(x)=max(0, x*W1 + b1)*W2 + b2
여기서 Linear transformation의 모양 자체는 모든 position에 대해 동일하게 가져가되, Layer마다는 각각 다른 parameter를 사용하도록 한다. 구조 자체는 1x1 Conv.와 비슷한 느낌으로 이해할 수 있다.
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
Embeddings and Softmax
Transformer에서는 각 Embedding Layer와 softmax전 적용하는 각 Linear transformation의 weight를 공유해서 학습한다. 즉, 고정된 Embedding을 사용하는 것이 아니라 Embedding weight도 계속 학습하게 된다. (다만 Embedding Layer에서는 weight를 √(d_model)만큼 곱해준다.)
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
Positional Encoding (PE)
모델 자체에서는 RNN/CNN을 사용하지 않는 만큼, Position에 대한 정보를 받을 수 없기 때문에 sequence 내의 상대/절대 position에 대한 정보를 별도로 추가해 줘야 한다.
여기서 position/거리에 대한 요소를 계산하기 위해 각 요소의 frequency에 따라 sin 내지는 cos 함수를 사용하고 있다.

class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
Model 전체
def make_model(src_vocab, tgt_vocab, N=6,
d_model=512, d_ff=2048, h=8, dropout=0.1):
"Helper: Construct a model from hyperparameters."
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn),
c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform(p)
return model# Small example model.
tmp_model = make_model(10, 10, 2)
None
Training
Batches & Masking
class Batch:
"Object for holding a batch of data with mask during training."
def __init__(self, src, trg=None, pad=0):
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
self.trg_mask = \
self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask
Training Loop
def run_epoch(data_iter, model, loss_compute):
"Standard Training and Logging Function"
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_iter):
out = model.forward(batch.src, batch.trg,
batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed = time.time() - start
print("Epoch Step: %d Loss: %f Tokens per Sec: %f" %
(i, loss / batch.ntokens, tokens / elapsed))
start = time.time()
tokens = 0
return total_loss / total_tokens
Training Data & batching
global max_src_in_batch, max_tgt_in_batch
def batch_size_fn(new, count, sofar):
"Keep augmenting batch and calculate total number of tokens + padding."
global max_src_in_batch, max_tgt_in_batch
if count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max(max_src_in_batch, len(new.src))
max_tgt_in_batch = max(max_tgt_in_batch, len(new.trg) + 2)
src_elements = count * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max(src_elements, tgt_elements)
Optimizer
4000번째 step까지는 warm-up단계라고 해서 낮은 learning rate부터 점차적으로 높여주는 방식을 쓰게 된다. 후에 점진적으로 learning rate를 낮춰가면서 fine-tuning과 비슷한 방식을 취하게 된다.
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step is None:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
Regularization - Label Smoothing
여기서 Label smoothing이란 target값에 대해 discrete한 값을 적용하는 것이 아닌 아주 작은 값을 이용해서 정답을 소수점으로 표현하고자 하는 방법이다. 이 모델에서는 정답에 대해 epsilon=0.1을 적용하고 있다. 이는 one-hot 분포(distribution)을 학습하는 대신 정답 단어에 대한 신뢰도(confidence)를 학습하려는 의도이다.
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(size_average=False)
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if len(mask) > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))
Label smoothing은 정답에 대한 신뢰도가 너무 높게 예측될 경우 penalize하는 효과가 있다.

Result & Conclusion
Result
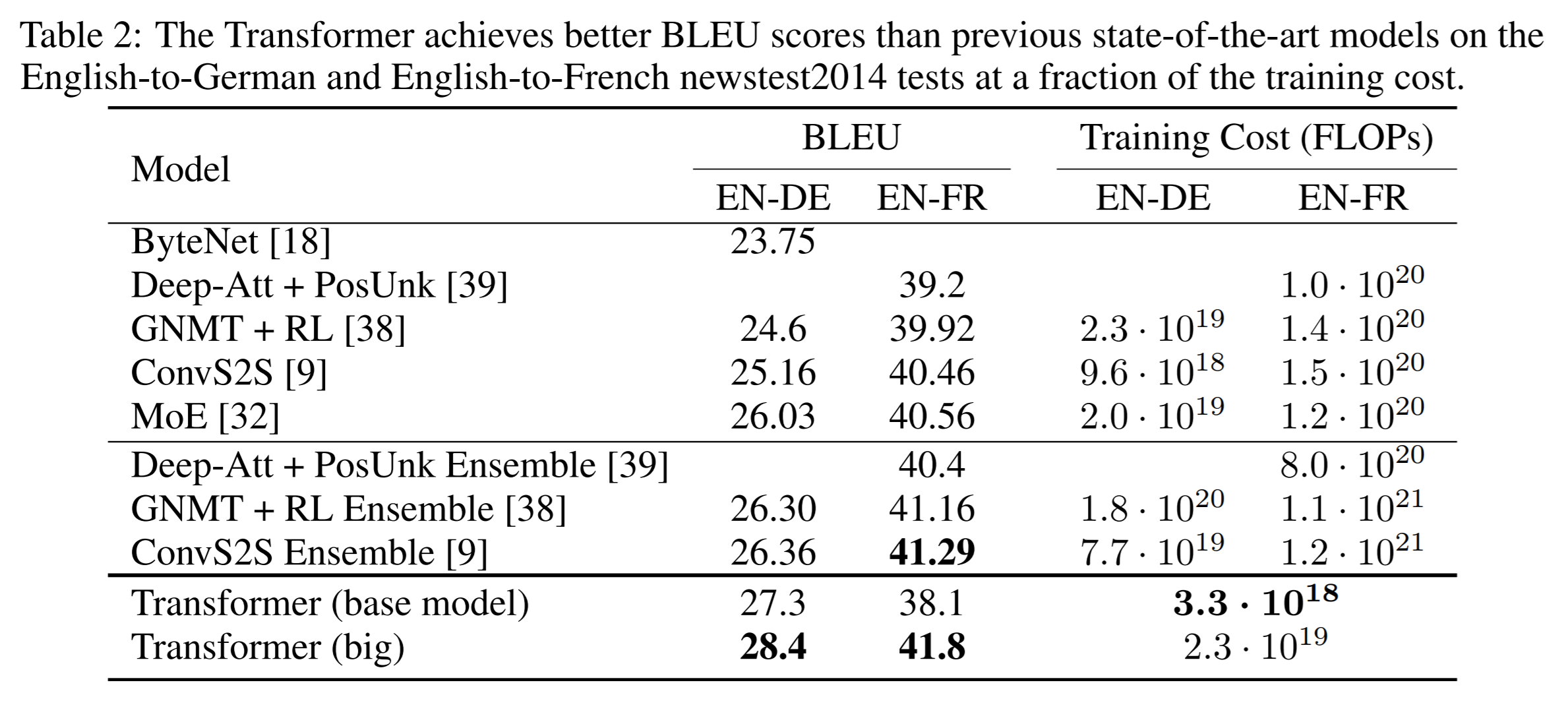
다른 모델에 비해 Training Cost가 훨씬 낮은 것을 볼 수 있다. 그에 비해 정확도는 오히려 SOTA를 달성하는 모습을 보여준다.
Conclusion
Transformer의 기본 요점 자체는 기존 방법에 비해 더 효율적인 연산을 하고자 함에 있는 것으로 보인다. 사실 성능 자체도 늘어난 점이 상당히 흥미롭다. 다만 이번 논문은 너무 복잡하고 어려운데다 RNN/CNN없이 Attention 연산만으로 학습을 하기에 이해가 어려웠다. 맨 위에 달아놓은 링크에서 Code도 구현을 하고 있으니 참고하는것이 좋을 듯 하다.