2019. 4. 8. 18:21ㆍ풀잎스쿨 NLP Bootcamp
참고자료: (김충현님 발표자료)
Combining supervised learning and unsupervised learning to improve word vectors
Introduction to Generative Pre-Training
towardsdatascience.com
Abstract
우선 시작하기 전, 우리가 NLP Task에 대해 모델을 만들때 어떤 식으로 학습하는지 생각해보자. 일단 Task가 주어지겠고, 그에 맞는 Labeling된 데이터셋이 존재할 것이며, 그 Task에 맞는 모델 구조를 사용함으로써 NLP Task를 NN모델을 통해 해결하고자 할 것이다.
사실 이러한 방식에는 문제가 있다. 우선, NLP에서는 Supervised Learning방법 자체가 한계가 있다는 점이다. 지금은 Wikipedia 페이지를 방대하게 모아놓은 데이터셋 같은 것이 존재하지만, 이러한 데이터셋은 그 목적(Task)이 분명하게 정해져 있다. 따라서 모든 Task에 대해 생각해 봤을때, NLP 데이터셋 중 Labeling된 것은 극히 일부분일 것이다.
또한 Text로 되어있는 것과 음성으로 된 자료는 다르다. 이는 책에서 보는 언어의 형태와 구어체가 다른 것으로도 쉽게 확인할 수 있다. 다시말해, 말로 직접 표현하는 언어와 텍스트 자료로 표현하는 언어는 서로 다른 의미를 가진다는 말이다.
그렇다면, 이러한 텍스트 데이터가 많다고 하면 문제가 해결될까? 그것도 아닌 것이, 많은 데이터로부터 좋은 representation을 어떻게 학습 시키느냐가 중요한 문제로 떠오른다. 좋은 Pretrained Word Embedding(GloVe, CoVe, Word2Vec 등)을 NLP 모델에서 다양하게 사용하고 있다는 사실이 이를 뒷받침해 준다.
그러면, Pretrained Word Embedding을 통해 NLP에서의 Transfer Learning을 시도한다면, 문제를 쉽게 해결할 수 있을까? 이것 또한 쉽지 않은 문제가 된다.
일단, 어떤 방식으로 NLP에서의 Transfer Learning을 해야하는지 그 방법이 확실히 정해져 있지 않다. CNN에서는 이미 Transfer Learning이 많이 쓰이고 있고, 그 방법이 어느정도 정해져 있다. 하지만 이는 Feature extraction을 하는 방법 자체가 이미 확실하게 정해져있고, 이를 통해 여러 학습 모델이 제시된다. NLP는 이와 같은 방법이 아직 정립되기 전이었다.
또한 NLP에서는 Embedding에 대한 문제가 있다. 어떤 방식을 통해 Embedding을 Optimize할 것인가에 대한 이야기인데, Embedding을 하는 방식에는 ELMo, CoVe등과 같이 여러 다양한 방식이 존재하기 때문이다.
이러한 문제들을 논문에서는 Embedding에 대한 이러한 문제점들을 Word-level이 아닌 Context-level로 구성하고, Unsupervised Learning을 통해 어떻게 Pretraining을 해야하는지에 대해 방법을 정립하고자 한다. 또한 Supervised Learning을 통한 Fine-tuning을 거쳐 Task에 맞는 NLP모델을 구성하는 가이드라인을 제시한다.
요약하자면 Unsupervised Learning을 통한 Pretrained-LM의 구축과 Supervised Learning을 통한 Task prediction구조를 통해 여러 종류의 NLP downstream task에 대해 'Generative'한 방법을 통한 text representation을 학습 모델을 제안한다.
Contribution
Model Architecture
Unsupervised Learning


이 단계에서는 Unsupervised Learning을 통한 Language Model을 구성한다. 여기서는 Transformer block을 사용해서 Language Model을 구성하는 것으로 나오는데, 토큰화 된 문장을 Token Embedding matrix로 구성하는 과정에서 Transformer의 decoder부분만 사용하게 된다. 대신 기존의 Transformer가 Encoder/Decoder 6쌍으로 구성되었다고 하면 여기서는 Decoder만 12개(Multi-head)로 구성한다는 점을 특징으로 잡을 수 있다.
간단히 요약하자면, 일단 문장단위로 Encoding(BPE)하고 Transformer Decoder를 거쳐 Context-level Embedding을 하는 과정을 통해 Unsupervised Learning을 사용한 LM을 학습한다.
Supervised Learning
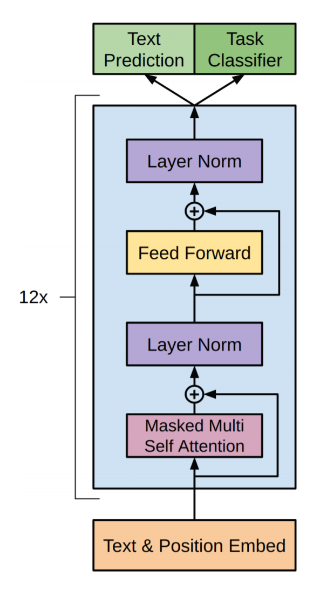
Supervised Learning부분은 크게 두 부분으로 나눠볼 수 있다. Text/Position Embedding부터 12개의 Decoder가 있는 부분인 Pretrained Model, 그리고 Task Prediction/Classification 부분까지 두 부분으로 나눠보자.
Pretrained Model에서는 Global한 NLP feature를 학습하도록 구성되어있다. 여기서 각 Embed는 Unsupervised에서도 언급했듯이 BytePair Encoding으로 구성되어있다. 이렇게 학습된 representation은 Context에 대해 소실되는 정보가 거의 없이 학습된다고 가정하고, 이를 Decoder를 통해 Task에 맞는 정답 Feature를 추출하고자 한다.
두번째로 Task prediction/classification부분이다. 여기서 기억해야 할 점은, Task Classifier 또는 Task Prediction과 같이 하나의 예상만 출력하지 않는다는 점이다. 논문에서도 이러한 구조를 Auxiliary Task라는 용어로 표현하고 있다. 쉽게 풀어 말하자면, 하나의 Task objective에 대해서만 학습하는 것 보다 Auxiliary objective(sub-task)를 같이 학습하는 것이 주요 task에 대한 정확도를 높여주는 것이다.
How to use (in different tasks)


사실 GPT가 pretrained model을 제시한다고 해서 모든 task에 대해 사용법이 전부 동일한 것은 아니다. 위 그림에서 보이듯이 Classification은 True/False 또는 category를 예측하기 위해 하나의 구조만 가지고 있지만, Similarity나 Multiple Choice의 경우 Context/Text를 비교하기 위해 각 부분마다 모델을 적용시킨 후, 이를 취합하는 구조를 보인다. 이와 같이 GPT 모델을 사용할 때는, 하고자 하는 Task에 맞춰 모델을 알맞게 구성해 줄 필요가 있다.
Result & Conclusion
Result

왼쪽 그래프는 Transformer Decoder의 갯수에 따른 정확도(accuracy)의 변화를 나타낸다. RACE(https://arxiv.org/abs/1704.04683)와 MultiNLI(https://arxiv.org/abs/1704.05426)는 각각 데이터셋이며, RACE의 경우 Question Answering(QA)를 목적으로 하며, MultiNLI의 경우 textual entailment 또는 NLI(Natural Language Inference)를 목적으로 한다. 결과에서도 보이듯, 두 데이터셋 모두 Layer의 갯수가 많아질수록 정확도가 비약적으로 상승하는 것을 볼 수 있다. (다만 12개 정도에서 정확도가 Converge하는 듯하다)
오른쪽 그래프는 점선(Transformer대신 LSTM 사용)과 실선(Transformer사용)을 통해 Transformer를 사용할때와 사용하지 않을 때의 차이를 보여주고 있다. 각 색상은 특정 Task를 나타낸다. 모든 Task에 대해 증가율의 차이는 있지만 모두 상대적으로 performance가 증가한 것을 볼 수 있다.

위 표에서는 Auxiliary Objective(sub-task)가 있을때와 없을때, 그리고 pre-training이 없을때의 성능을 보여준다.
위 결과중 왼쪽의 4가지 Task와 오른쪽 4가지 Task의 결과가 다른데, 이는 데이터셋의 크기가 다르기 때문이다. 즉, 데이터셋이 클수록(QQP, MNLI, QNLI, RTE) auxiliary task가 성능 개선에 영향이 더 크며, 작을수록(CoLA, SST2, MRPC, STSB) auxiliary task없이 학습하는 것이 오히려 성능에 도움이 되는 것을 확인할 수 있다.
Transformer의 사용 여부에 대해서도 성능을 측정하고 있는데, 모든 경우에 대해 LSTM 대신 Transformer를 사용하는 것이 성능 개선에 도움이 되는 것을 확인할 수 있다.
또한 pre-training의 유무에 대해서도 성능을 측정하는데, full모델에 비해 pre-training이 없을 경우 전체적으로 성능이 매우 감소하는 것을 확인할 수 있다. (여기서 pre-training을 사용하지 않는다는 것은 unsupervised pre-training에 사용되는 구조를 모두 넘겨버리는 것을 말한다. 즉, supervised부분만 사용하는 것)
Conclusion
사실 GPT-1은 BERT에 비해 그리 주목받지 못한다. 이유가 몇가지 있는데, 우선 BERT가 범용적으로 쓰이기 더 용이하다는 점, 그리고 성능면에서도 BERT에 비해 좋다는 소식이 들리지 않기 때문도 있다(SQuAD 1.1이나 2.0을 살펴보면 GPT에 대한 성능 결과가 아무것도 없다).
하지만 그럼에도 불구하고 이 논문을 살펴봐야 할 이유는 있는데, Decoder로서 Transformer를 Pre-trained Language Model생성에 어떻게 사용하고 있는가에 대한 좋은 예시가 바로 GPT이기 때문이다. 다른 많은 부분은 BERT와 비슷하게 가는 부분이 많아도 이 점 하나는 알아갈만한 포인트로 보인다. (그리고 사실 BERT와 GPT-1은 많은 부분이 흡사하다)